Branding & frontend

Background
I was doing work at a stealth product at the time that used the common strategy of:
- Embed documents using OpenAI's
ada-02; - Store them in a vector database;
- Retrieve the top5 documents from a vector database;
- Use the retrieved documents as part of a prompt to a LLM.
The product was not perfoming as we expected and upon analyzing, we came to the conclusion that the problem was the retrieved results from the vector database. After trying a bunch of techniques (e.g. HyDE), I was pretty sure I could myself create a better vector database.
I'd say I had success since Memora had a 71% search accuracy increase in a reduced MS-MARCO benchmark while maintaining a p99 latency of 400ms.
Tech report
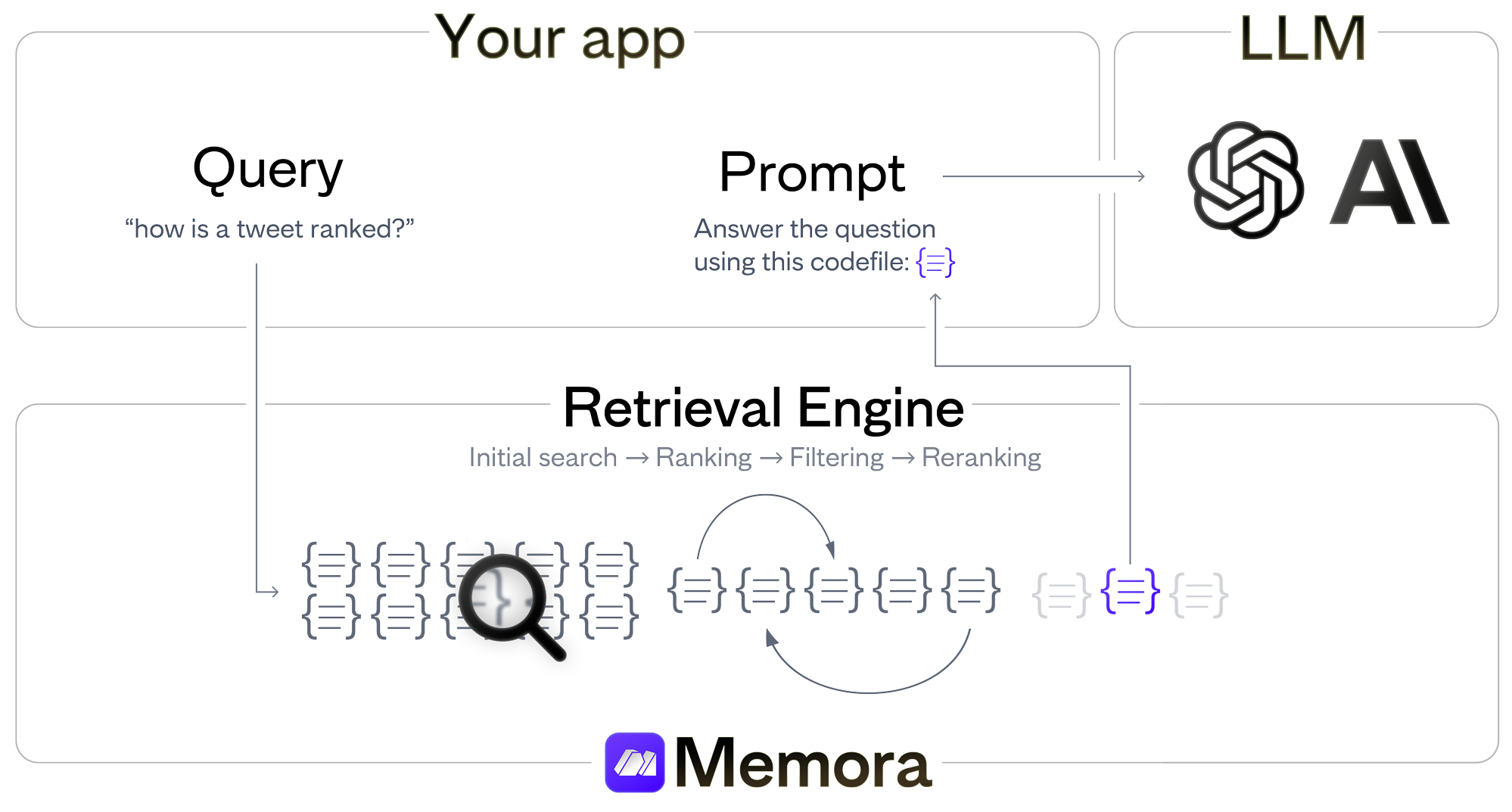
Here's how Memora works internally when you upload a document to it:
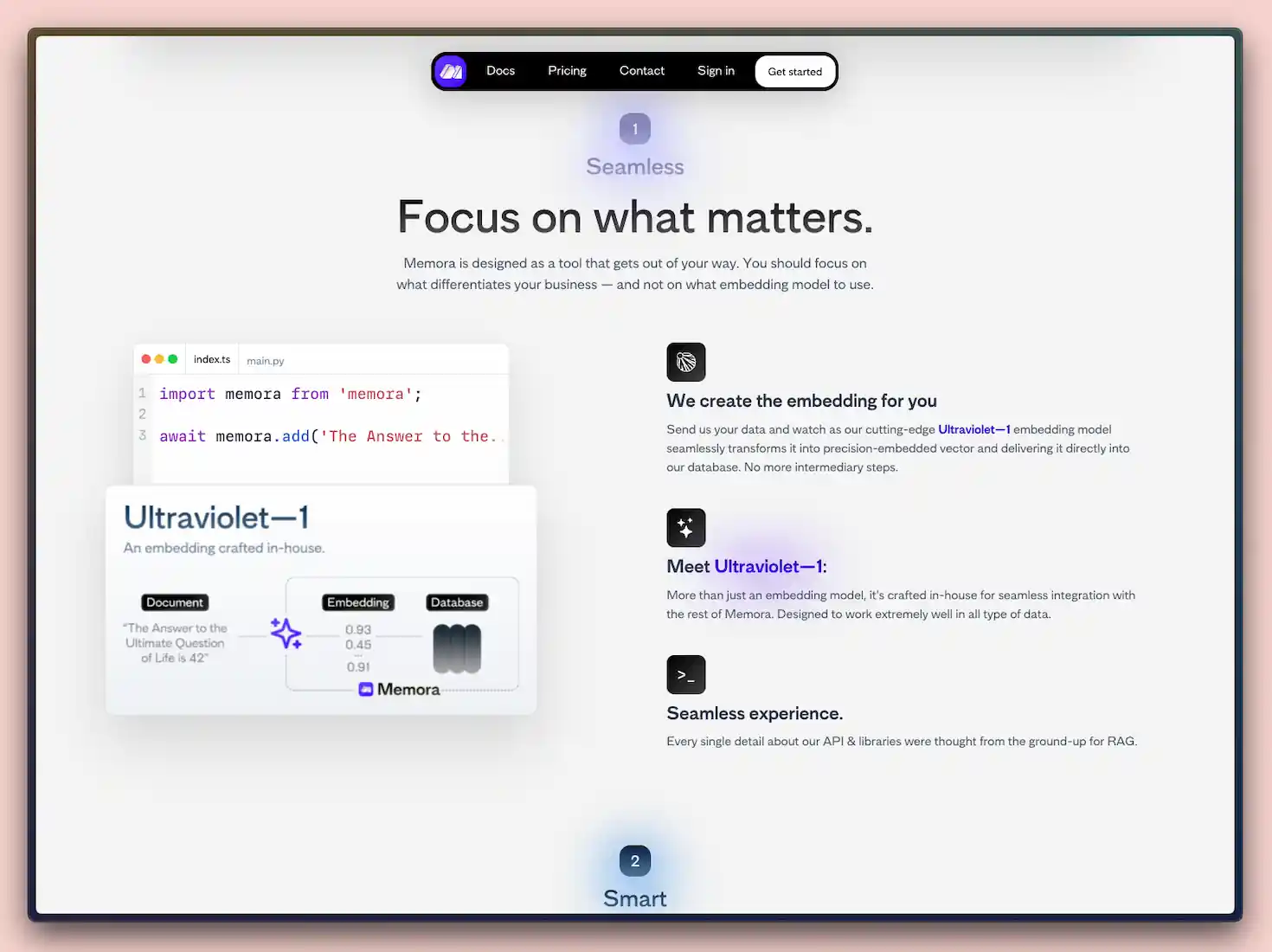
- Create an embedding of it using a custom finetuned version of e5-large named
Ultraviolet—1;- (Chunk them if needed).
—
- Store the embedding in Weaviate.
And the retrieval:
- Retrieve the top 5k documents using k-nearest neighbor search;
- Rerank the 5k documents using ms-marco-MiniLM-L-12-v2;
- Rerank the top 50 using a custom finetuned version of RankT5 named
Retrieval Engineand return the top 50.
Both finetuned models (e5-large's Ultraviolet—1 & RankT5's Retrieval Engine) were finetuned on synthetic data created using gpt-3.5-turbo:
Ultraviolet—1on ~190M tokens;Retrieval Engineon ~140M tokens.
On finetunning
I'm referring as finetunning for clarity only, the more fitting name is "continued training" given that the initial layers were not frozen, the learning rate was only slightly lowered and the amount of data was significant — for instance, the 190M tokens that Ultraviolet—1 was trained on represents around 20% of e5-larges's training dataset.
On inference
All of Memora's infra was in AWS. In terms of the ML model I used AWS's inferentia 2 chip which is cheaper than GPUs and it runs good enough — at least for our usecase.
Outcome
Due to a couple of reasons I won't go into here, I stopped having the confidence Memora as a startup would work out. As a consequence of it, I left the project a bit after launch. AFAIK, my ex-cofounder still runs it.
Still, as is the case with everything I do, the main reason I decided to work on Memora was for curiosity and in hopes of learning more in the unstructured retrieval space, and through that lens, my time spent on Memora was a major success.
I got up-to-date in the field's literature and was able to implement SOTA methods and bring it to the market, and even got ideas on how to improve on those SOTA methods — for instance, RankT5 was created from T5 (which is an outdated OSS LLM), but what if you apply the same method but with Llama-3 as the base LLM? It'd would definetively achieve SOTA level perfomance as a neural reranker.